公司网站建设设计服务seo搜索引擎优化步骤
ViT:视觉 Transformer
- 网络结构
- Transformer 编码器
- MLP 头
- CNN 和 Transformer
网络结构
Transformer 的优势:注意力机制相当于一个多标签检索系统,位置嵌入能知道每个单词的位置,而且适合并行。
尝试把 Transformer 迁移到视觉领域。

ViT 在 Transformer 基础上:
- 输入:为了把图像空间序列化,引入了图片切分预处理、patch+位置嵌入
- 主干:Transformer
- 输出:MLP头及分类器
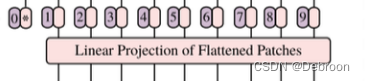
图片切分预处理:如输入图片大小为 224x224,将图片分为固定大小的patch(16x16),则每张图像会生成 224 ∗ 224 16 ∗ 16 = 196 个 p a t c h \frac{224 * 224}{16*16}=196个patch 16∗16224∗224=196个patch ,把这些图像块摆成一行,即输入序列长度为196。

在图片块和 Transformer 之间,还有一个全连接层,对维度进行缩放。

patch+位置嵌入:给每个图像块,添加位置。
数学公式:
- z 0 = [ x c l a s s ; x p 1 E ; x p 2 E ; ⋯ ; x p N E ] + E p o s , E ∈ R ( P 2 ⋅ C ) × D , E p o s ∈ R ( N + 1 ) × D (1) \begin{gathered} z_0 =[\mathbf{x}_{\mathrm{class}};\mathbf{x}_{p}^{1}\mathbf{E};\mathbf{x}_{p}^{2}\mathbf{E};\cdots;\mathbf{x}_{p}^{N}\mathbf{E}]+\mathbf{E}_{pos}, \mathbf{E}\in\mathbb{R}^{(P^{2}\cdot C)\times D},\mathbf{E}_{pos}\in\mathbb{R}^{(N+1)\times D} \text{(1)} \end{gathered} z0=[xclass;xp1E;xp2E;⋯;xpNE]+Epos,E∈R(P2⋅C)×D,Epos∈R(N+1)×D(1)
z 0 z_0 z0 的输入图像进行编码, z 0 z_0 z0表示输入图像的嵌入向量。
x p ( 1 ) \mathbf{x}_{p}^{(1)} xp(1) 表示第一个图像块的嵌入向量, E \mathbf{E} E 是位置嵌入矩阵,用于将图像块的位置信息编码到嵌入向量中。
E pos \mathbf{E}_{\text{pos}} Epos 是位置编码矩阵,用于将位置信息添加到输入数据中。
x c l a s s \mathbf{x}_{\mathrm{class}} xclass向量用于解决图像分类问题,将整个图像的类别信息引入Transformer模型。
Transformer 编码器
计算出 z 0 z_0 z0 后,输入到 Transformer 编码器(没有用解码器):

输入部分:
-
Layer Norm:把 z 0 z_{0} z0 归一化,再 Q、K、V 分离。
-
残差连接,减轻梯度消失、爆炸。
MSA:多头注意力,每个注意力头负责捕捉图像的不同局部信息,把图像中多个差异拿出来进行学习。
MLP 头
多层感知机(Multilayer Perceptron,MLP)是一种前馈神经网络:
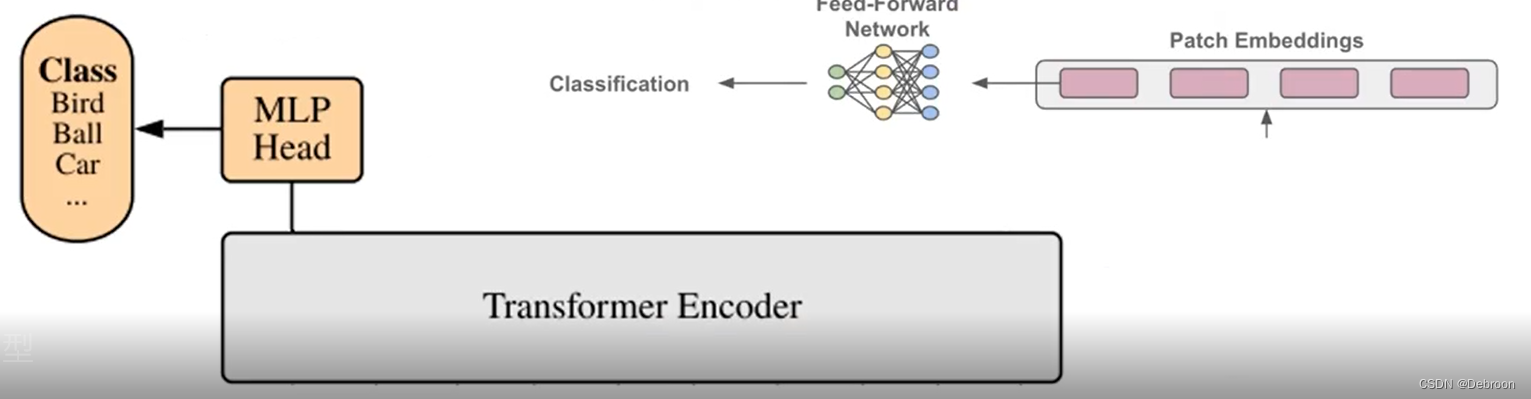
MLP 分类头就是一个全连接层。
TA 的工作流程:
- 接受编码器的输出
- 先把 x c l a s s \mathbf{x}_{\mathrm{class}} xclass 提取出来
- 再分类
ViT编码器的输出将是一个形状为(4, 16, 512)的张量。
- 第一个维度4表示批次大小,即有4张输入图像。
- 第二个维度16表示每张图像被分割为16个图像块。
- 第三个维度512表示每个图像块的表示维度,即隐藏层的维度。
这个编码器输出可以包含输入图像的全局信息和局部信息的组合。
每个图像块的表示捕捉了该图像块的局部特征,而整个编码器输出则综合了所有图像块的信息,包括它们之间的关系,从而提供了更全局的图像信息。
CNN 和 Transformer
CNN擅长处理图像的局部特征,而ViT模型擅长处理图像的全局特征和整体类别信息。
选择CNN模型的情况:
- 当任务关注图像的局部特征,比如纹理、形状、边缘等。
- 当处理的图像较大,且局部特征在整体中仍然具有较大的重要性。
- 当数据集较小,而且已经有了一些经典的CNN模型在类似任务上表现良好。
选择ViT模型的情况:
- 当任务需要关注图像的全局特征和整体类别信息。
- 当处理的图像相对较小,且全局结构和上下文信息对于任务很重要。
- 当数据集较大,可以利用更强大的模型来提取全局信息和学习更复杂的特征。