理县网站建设公司网站搭建一般要多少钱
引言:
处理大量PDF文档的文本提取任务可能是一项繁琐的工作。本文将介绍一个使用Python编写的工具,可通过简单的操作一键提取大量PDF文档中的文本内容,极大地提高工作效率。
import wx
import pathlib
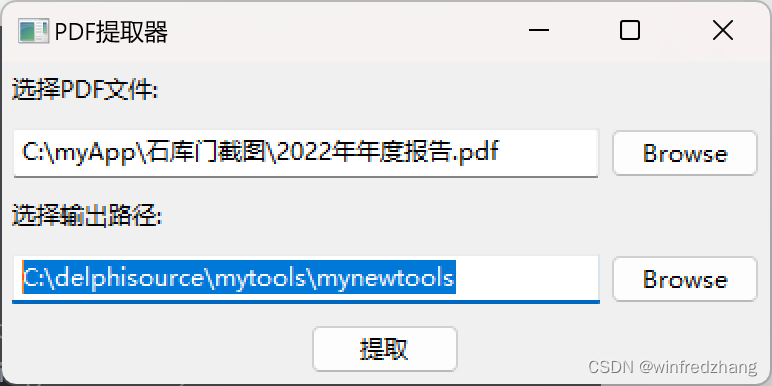
import fitzclass PDFExtractor(wx.Frame):def __init__(self, parent, title):super(PDFExtractor, self).__init__(parent, title=title, size=(400, 200))panel = wx.Panel(self)vbox = wx.BoxSizer(wx.VERTICAL)self.file_picker = wx.FilePickerCtrl(panel, style=wx.FLP_DEFAULT_STYLE | wx.FLP_USE_TEXTCTRL)self.save_picker = wx.DirPickerCtrl(panel, style=wx.DIRP_DEFAULT_STYLE | wx.DIRP_USE_TEXTCTRL)self.extract_button = wx.Button(panel, label="提取")self.extract_button.Bind(wx.EVT_BUTTON, self.on_extract)vbox.Add(wx.StaticText(panel, label="选择PDF文件:"), 0, wx.ALL | wx.EXPAND, 5)vbox.Add(self.file_picker, 0, wx.ALL | wx.EXPAND, 5)vbox.Add(wx.StaticText(panel, label="选择输出路径:"), 0, wx.ALL | wx.EXPAND, 5)vbox.Add(self.save_picker, 0, wx.ALL | wx.EXPAND, 5)vbox.Add(self.extract_button, 0, wx.ALL | wx.CENTER, 5)panel.SetSizer(vbox)def on_extract(self, event):pdf_path = self.file_picker.GetPath()save_path = self.save_picker.GetPath()if pdf_path and save_path:progress_dialog = wx.ProgressDialog("提取进度", "正在提取...", maximum=100, parent=self)try:with fitz.open(pdf_path) as doc:total_pages = len(doc)progress = 0for index, page in enumerate(doc):text = page.get_text()output_file = pathlib.Path(save_path) / f"page_{index + 1}.txt"output_file.write_text(text, encoding="utf-8")progress = int((index + 1) / total_pages * 100)progress_dialog.Update(progress, f"正在提取第 {index + 1} 页 / 共 {total_pages} 页")progress_dialog.Update(100, "提取完成!")wx.MessageBox("提取完成!", "成功", wx.OK | wx.ICON_INFORMATION)except Exception as e:wx.MessageBox(str(e), "错误", wx.OK | wx.ICON_ERROR)finally:progress_dialog.Destroy()else:wx.MessageBox("请选择PDF文件和输出路径!", "错误", wx.OK | wx.ICON_ERROR)def main():app = wx.App()frame = PDFExtractor(None, "PDF提取器")frame.Show()app.MainLoop()if __name__ == '__main__':main()在这个示例中,我们创建了一个wx.ProgressDialog对象,用于显示提取进度。在提取每一页的文本时,我们使用enumerate函数获取当前页的索引,并根据总页数计算提取进度的百分比。然后,我们使用progress_dialog.Update方法更新进度条的进度和显示的文本。
请注意,由于提取过程可能需要一些时间,所以我们使用进度条对话框来显示进度并阻止用户的交互。在提取完成后,进度条对话框会自动关闭。
其中:
1)文档选择:
self.file_picker = wx.FilePickerCtrl(panel, style=wx.FLP_DEFAULT_STYLE | wx.FLP_USE_TEXTCTRL)2、文件夹选择:
self.save_picker = wx.DirPickerCtrl(panel, style=wx.DIRP_DEFAULT_STYLE | wx.DIRP_USE_TEXTCTRL)3、进度显示:
progress = int((index + 1) / total_pages * 100)progress_dialog.Update(progress, f"正在提取第 {index + 1} 页 / 共 {total_pages} 页")progress_dialog.Update(100, "提取完成!")4、最重要的:获得pdf中的文本:
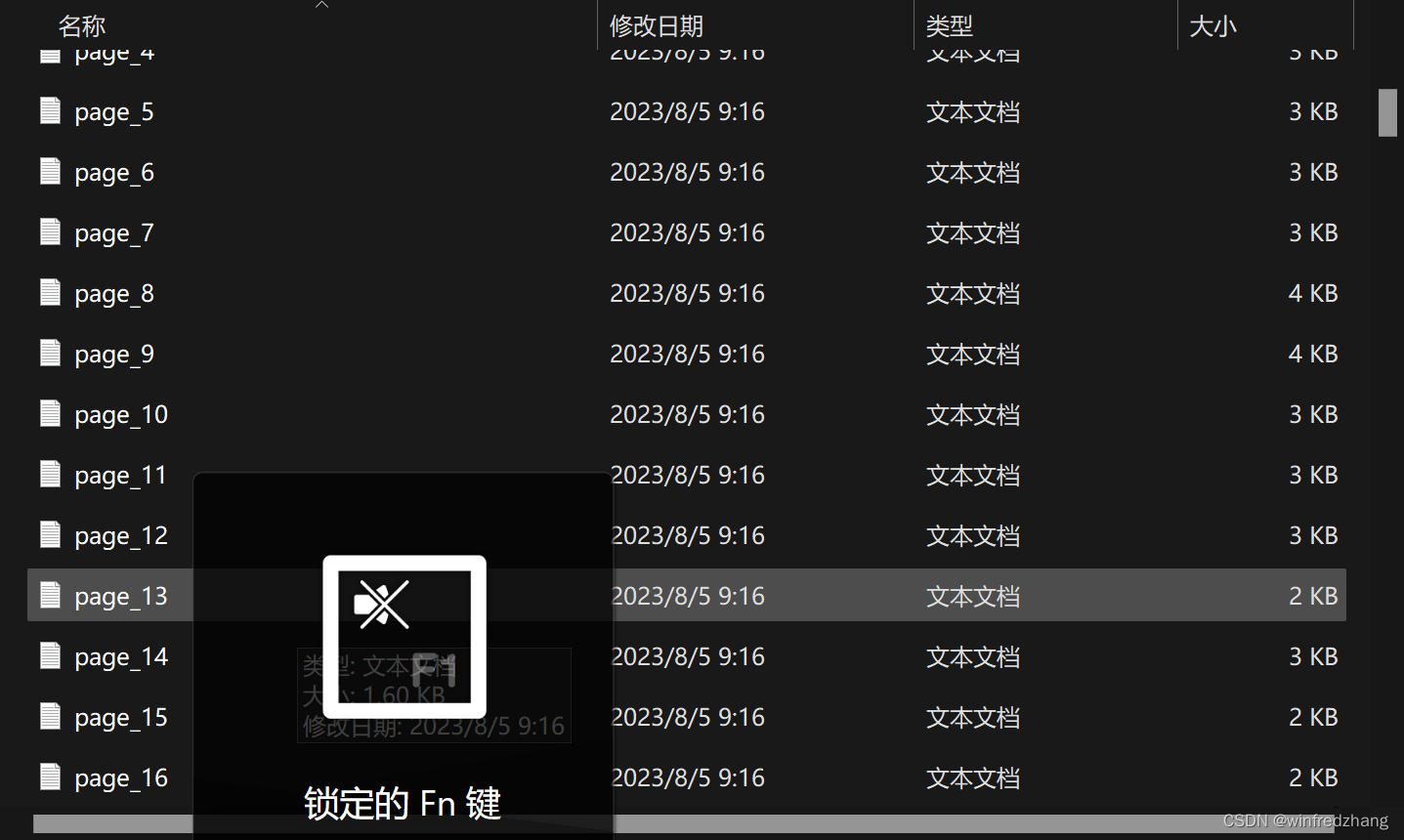
with fitz.open(pdf_path) as doc:total_pages = len(doc)progress = 0for index, page in enumerate(doc):text = page.get_text()output_file = pathlib.Path(save_path) / f"page_{index + 1}.txt"output_file.write_text(text, encoding="utf-8")结果如下: