网站解析要多久优化方案英语
文章目录
- 1. Multi-Head Attention (MHA)
- 2. Multi-head Latent Attention (MLA)
- 2.1 低秩压缩
- 2.2 应用RoPE
- 2.3 矩阵融合
- 参考资料
在讲解MLA之前,需要大家对几个基础的概念(KV Cache, Grouped-Query Attention (GQA), Multi-Query Attention (MQA),RoPE)有所了解,这些有助于理解MLA是怎么工作的,为什么需要这么做。
这里给出概念及对应的讲解博客:
- MHA,MQA,GQA及KV Cache:【大模型】MHA,MQA,GQA及KV Cache详解
- 旋转位置编码RoPE:【大模型】旋转位置编码(Rotary Position Embedding,RoPE)
1. Multi-Head Attention (MHA)
首先跟着DeepSeek V2的论文简单回顾一下Multi-Head Attention(MHA)的计算过程,首先给出各个变量的含义如下:
- d d d 代表输出维度(input dim)
- n h n_h nh 代表头数(head数)
- d h d_h dh 代表每个头的维度
- h t h_t ht 代表输入的第 t 个向量
- l l l 代表 transformer 的层数
主要公式如下:

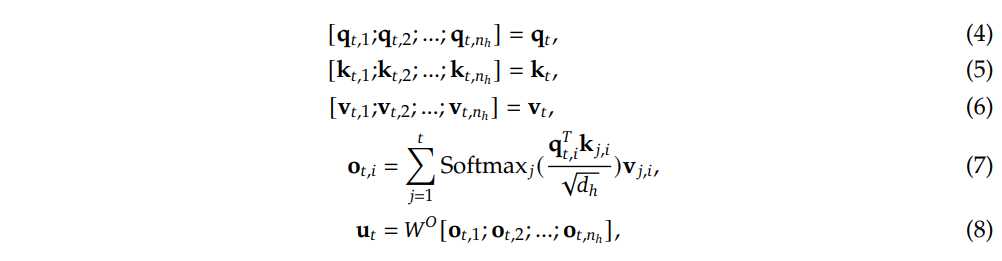
下面来介绍下公式的含义:
- W Q , W K , W V ∈ R d h n h ∗ d W_Q, W_K, W_V \in R^{d_hn_h*d} WQ,WK,WV∈Rdhnh∗d 表示输入维度,公式(1)-(3)中我们只使用一个矩阵来处理多头(multi-head)
- 公式(4)-(6)表示对 q t , k t , v t ∈ R d h n h q_t, k_t, v_t \in R^{d_hn_h} qt,kt,vt∈Rdhnh 进行分割,可以得到每个头对应的 q, k, v
- 公式(7)表示对q, k 进行softmax操作,然后再乘上v
- 公式(8)表示对多头输出的结果进行拼接操作,再乘上 W o W^o Wo得到最终的输出
下面我们分析下,KV Cache的占用量:
对于标准的MHA而言,对于每一个token,KV Cache占用的缓存的大小为 2 n h d h l 2n_hd_hl 2nhdhl。
后续我们要介绍的MLA就是致力于在推理过程中降低 n h d h n_{h} d_{h} nhdh。
2. Multi-head Latent Attention (MLA)
参考资料:全网最细!DeepSeekMLA 多头隐变量注意力:从算法原理到代码实现
2.1 低秩压缩
MLA的核心是对KV做了低秩压缩(Low-Rank Key-Value Joint Compression),在送入标准的MHA算法前,用一个更短的向量来表示原来的长向量,从而大幅减少KV Cache空间。
- 论文地址:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
这里给出MLA的整体结构图:

这里先给出图中一些字母和符号的含义,方便我们后续理解。
- q: query
- k: key
- v: value
- h t h_t ht: 输入的第 t 个向量
- C: compress 压缩
- R: RoPE 旋转位置编码
- D: down 下采样,降维
- U: up 上采样,升维
MLA的核心是对KV做了低秩压缩(Low-Rank Key-Value Joint Compression)来减少KV cache,公示如下:

-
公式(9)中通过下采样矩阵,对输入 h t h_t ht 进行压缩得到中间表示 C t K V {C_t}^{KV} CtKV,再基于公式(10)和(11)进行上采样升维度还原KV。
-
KV cache占用空间大幅下降。从MLA的架构图上可以看到,需要缓存的元素为 C t K V {C_t}^{KV} CtKV和 k t R {k_t}^{R} ktR。这里我们先主要关注 C t K V ∈ R d c {C_t}^{KV} \in R^{d_c} CtKV∈Rdc,且 d c < < n h d h d_c<<{n_h}{d_h} dc<<nhdh 。前面我们提到,对于标准的MHA而言,每一个token的KV Cache大小为 2 n h d h l 2n_hd_hl 2nhdhl。而对MLA而言,每一步token的推理产生的缓存变成 d c l d_c l dcl,缓存的矩阵大小相比于原始KV做了压缩,因此缓存量大幅下降。(补充:deepseek v2中 d c d_{c} dc被设置为 4 d h 4 d_{h} 4dh)
-
在MLA中,同时也压缩了 query 向量。我们知道在KV Cache中,Q的作用只发生在当下,无需缓存。但是在模型训练的过程中,每个输入的token会通过多头注意力机制生成对应的query、key和value,这些中间数据的维度往往非常高,因此占用的内存量也相应很大。所以论文中也提到为了降低训练过程中的激活内存activation memory,DeepSeek-V2还对queries进行低秩压缩。对Q的压缩方式和K、V一致,依然是先降维再升维,这个操作并不能降低KV Cache,而是降低内容占用,另外一方面也可以使得query 和key, value 能在同一个低维空间进行一致性表示。
2.2 应用RoPE
上面这种低秩压缩的计算方式,对于RoPE旋转位置编码是有影响的,因为压缩操作可能已经丢失了某些信息,使得位置编码不能直接和有效地反映原始Q和K的位置关系。因此,不能直接在压缩后的向量上应用RoPE。
那么可不可以在解压后的向量上应用RopE呢?
可以,但是影响效率,因为前面已经说过不显示计算解压后的向量,而是直接应用压缩后的向量。
如何解决呢?Deepseek-V2设计了两个新的向量,单独应用RoPE,将位置信息写入这个新的向量中。
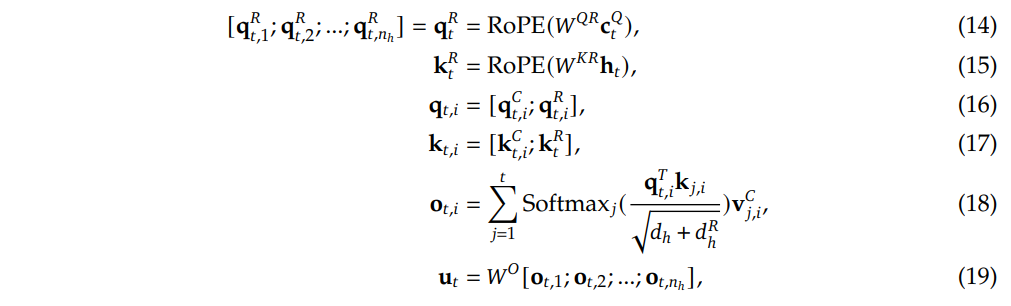
其中, q t , i R {q_{t,i}}^{R} qt,iR 和 k t R {k_t}^R ktR 就是应用了RopE的新向量。

-
需要注意的是,在对 k t R {k_t}^R ktR 进行编码时,它是直接从input hidden h t h_t ht上来的,也就是k向量不需要进行先降维、后升维的操作。
-
压缩完、且RoPE编码完之后,最后将这4个变量( q t C = W U Q c t Q q_{t}^{C}=W^{U Q} c_{t}^{Q} qtC=WUQctQ、 k t C = W U K c t K V \mathbf{k}_{t}^{C}=W^{U K} \mathbf{c}_{t}^{K V} ktC=WUKctKV、 q t R \mathbf{q}_{t}^{R} qtR、 k t R \mathbf{k}_{t}^{R} ktR)分别拼接起来,形成 带信息压缩 的和 带位置信息 的向量。
- 带信息压缩:Query—— q t C \mathbf{q}_{t}^{C} qtC,Key—— k t C \mathbf{k}_{t}^{C} ktC
- 带位置信息:Query—— q t R \mathbf{q}_{t}^{R} qtR,Key—— k t R \mathbf{k}_{t}^{R} ktR
-
最后将拼接后的 q t , i q_{t,i} qt,i 和 k t , i k_{t,i} kt,i,结合 k t C {k}_{t}^{C} ktC来进行后续的multi-head attention的计算(也就是seft-attention的常规计算那一套流程)。
2.3 矩阵融合
从前面的整体结构图中,我们看到向量 c t K V \mathbf{c}_{t}^{K V} ctKV、 k t R \mathbf{k}_{t}^{R} ktR需要缓存以进行生成。 在推理过程中,常规做法需要从 c t K V \mathbf{c}_{t}^{K V} ctKV中恢复 k t C \mathbf{k}_{t}^{C} ktC 和 v t C \mathbf{v}_{t}^{C} vtC以进行注意力计算。
- 在DeepSeek V2中巧妙地利用了矩阵融合操作,将上采样矩阵 W U K W^{UK} WUK融合到 W U Q W^{UQ} WUQ中,并将 W U V W^{UV} WUV融合到 W O W^{O} WO中。也就是说不需要显示地去计算得到 k t C {k}_{t}^{C} ktC 和 v t C {v}_{t}^{C} vtC,而可以直接基于 C t K V {C_t}^{KV} CtKV 进行计算,避免了在推理过程中重复计算 k t C {k}_{t}^{C} ktC 和 v t C {v}_{t}^{C} vtC的开销。
这里解释一下什么是矩阵融合(can be absorbed into)操作。后续计算的时候甚至都不需要显示进行融合操作,而是由神经网络自动通过训练进行的,我们仅需要对压缩后的隐向量操作即可。

最终,MLA单个Token产生的缓存包含了两个部分,即 ( d c + d h R ) l \left(d_{c}+d_{h}^{R}\right) l (dc+dhR)l,实现了计算量小且效果优于MHA的结果。

参考资料
- DeepSeekV2之MLA(Multi-head Latent Attention)详解
- 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA (By 苏剑林)
- deepseek技术解读(1)-彻底理解MLA(Multi-Head Latent Attention)
- 全网最细!DeepSeekMLA 多头隐变量注意力:从算法原理到代码实现
- 一文通透DeepSeek V2——通俗理解多头潜在注意力MLA:改进MHA,从而压缩KV缓存,提高推理速度